1、准备模块
1、openpyxl excel处理库
2、requests 网络请求库
3、bs4 BeautifulSoup,网页数据处理库
2、网页结构分析
需要抓取的网页:
http://yyk.39.net/doctors/xinlike/c_p1/
总共680页,URL的区别就是c_p{},后边跟上页数
需要抓取的内容:
首页单个医生信息

详情页医生的一些介绍

查看网页结构:
列表中的一些信息
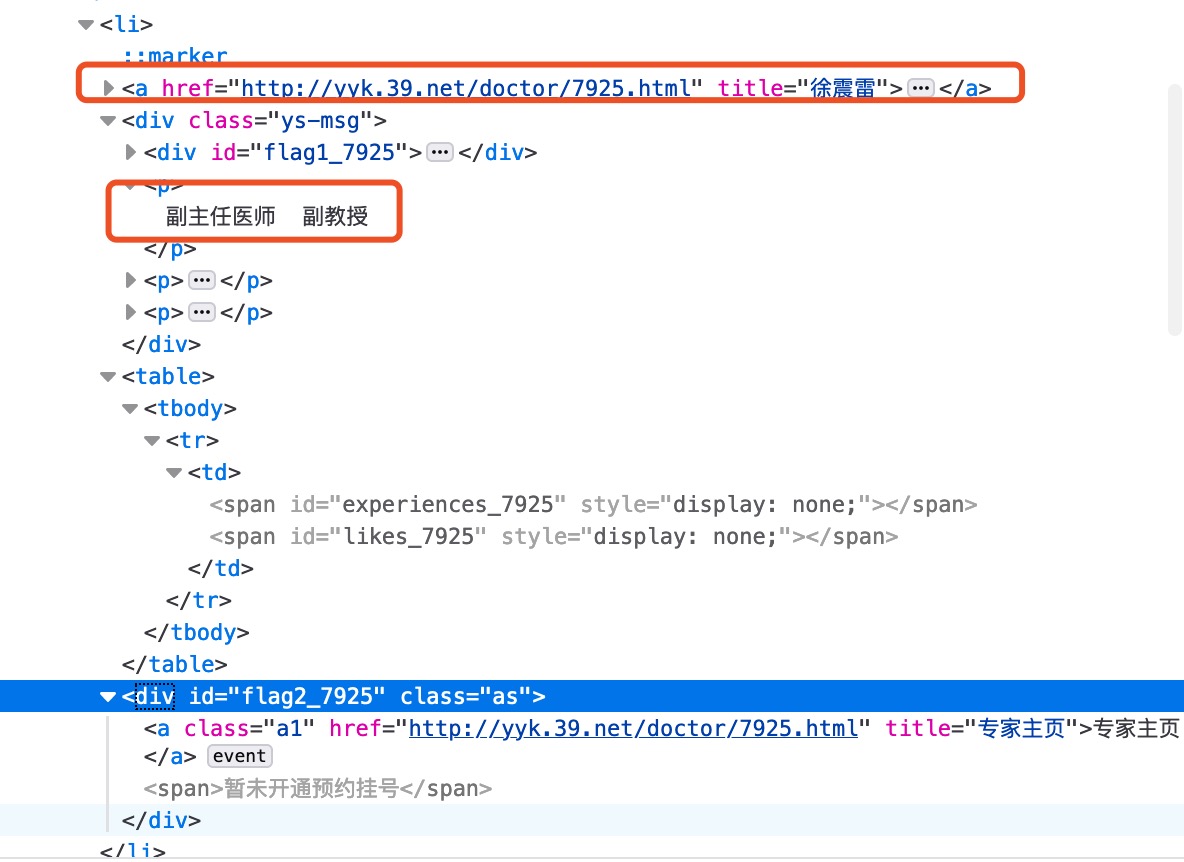
擅长领域
执业经历

3、核心代码
获取excel中的sheet,每100页放入一个sheet
# 获取excel中的sheet
def get_sheet_object(sheet_index,excel_data):
# excel_data = openpyxl.load_workbook("doctors_with_intro.xlsx")
sheet_page_index = int(sheet_index/100) + 1;
# print(sheet_page_index)
try:
return excel_data[str("Sheet"+str(sheet_page_index))]
except Exception as e:
excel_sheet = excel_data.create_sheet("Sheet"+str(sheet_page_index))
title_string = ['编码', '名称', '主页', '头像', '擅长领域', '执业经历', '医院名称', '医院地址', '科室名称', '科室地址', '科室2名称', '科室2地址']
for index in range(len(title_string)):
excel_sheet.cell(row=1,column=index+1).value = title_string[index]
return excel_sheet
获取列表内信息,查找出来的div的上一级标签就是li,使用div_parent[index]就能找到div同级标签。使用get[className]就能获取相应标签的各种属性。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/67.0.3396.99 Safari/537.36'
}
html_content = requests.get(url,headers=headers)
html_content_text = html_content.text.strip()
html_content_text = html_content_text.replace('\n','')
soup = BeautifulSoup(html_content_text,'lxml')
# 通过select找到 li 下div的标签
li_list = soup.select('li div[class="ys-msg"]')
if len(li_list) == 0:
with open(f'doctor_pic/errorlog.txt', 'a+', encoding='utf-8') as f:
f.write(f'抓取 {page_number} 数据失败\n')
dict = {}
for div in li_list:
div_parent = div.parent()
获取医生简介,使用requests获取数据,处理完返回。这里有个坑,擅长领域并不是每个都有详情的,要根据请求到的数据处理。
# 获取医生简介
def get_doctor_info(doctor_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/67.0.3396.99 Safari/537.36'
}
html_content = requests.get(doctor_url, timeout=10, headers=headers)
html_content_text = html_content.text.strip()
html_content_text = html_content_text.replace('\n','')
soup = BeautifulSoup(html_content_text,'lxml')
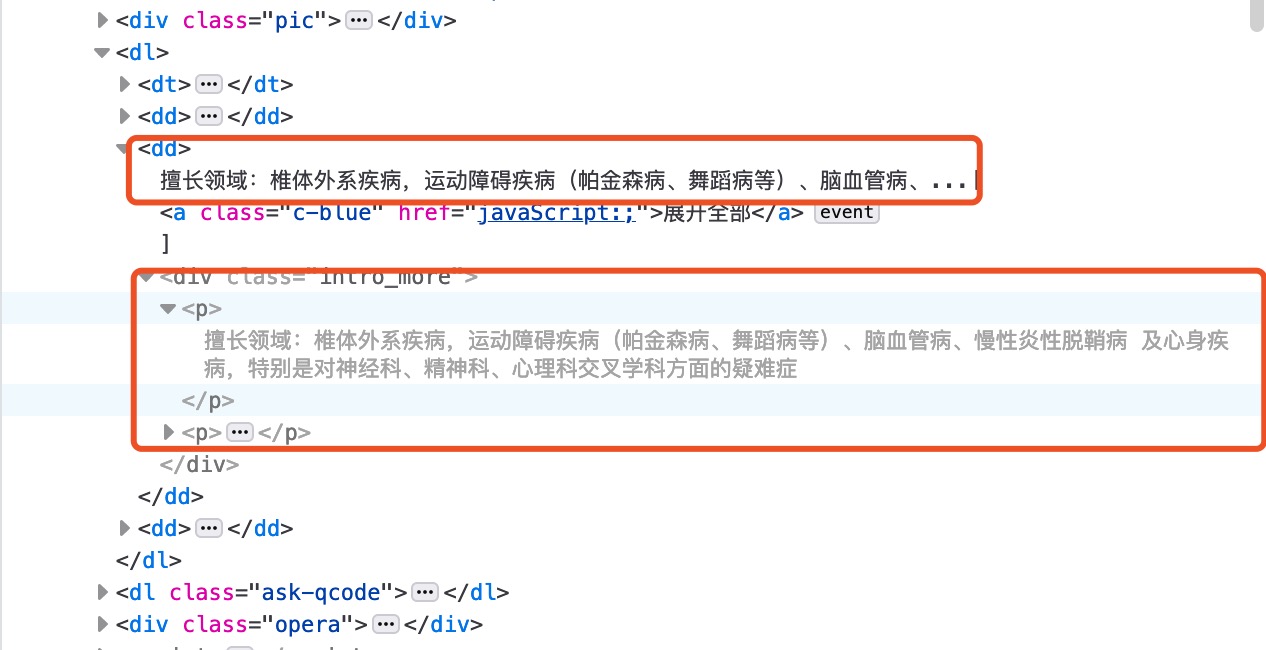
intro_list = soup.select('div[class="intro_more"] p')
history_list = soup.select('div[class="hos-guide-box1"] p')
history_string = ''
for i in history_list:
history_string += str(i.get_text() + '\n')
if len(intro_list) > 0:
intro_string = intro_list[0].get_text().strip()
return ((intro_string[5:] if (len(intro_string) > 5) else intro_string), history_string)
else:
intro_more_list = soup.select('dl dd')
if len(intro_more_list) > 2:
intro_more_string = intro_more_list[2].get_text().strip()
else:
intro_more_string = ''
intro_more_string = intro_more_string.replace('\t','')
return ((intro_more_string[5:] if (len(intro_more_string) > 5) else intro_more_string),history_string)
下载医生图片
# 下载医生图片
def download_doctor_icon(path, img_url, img_code, page_number):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/67.0.3396.99 Safari/537.36'
}
r = requests.get(img_url, timeout=10, headers=headers)
print(f'下载{img_code}图片成功!')
with open(f'{path}/{img_code}-{page_number}.png', 'wb') as f:
f.write(r.content)
except Exception as e:
print(f'下载{img_code}图片失败!')
print(f'错误代码:{e}')
with open(f'{path}/errorlog.txt', 'a+', encoding='utf-8') as f:
f.write(f'错误代码:{e}---下载 {img_url} 图片失败\n')
4、最后开始请求
抓取结果
医生信息列表
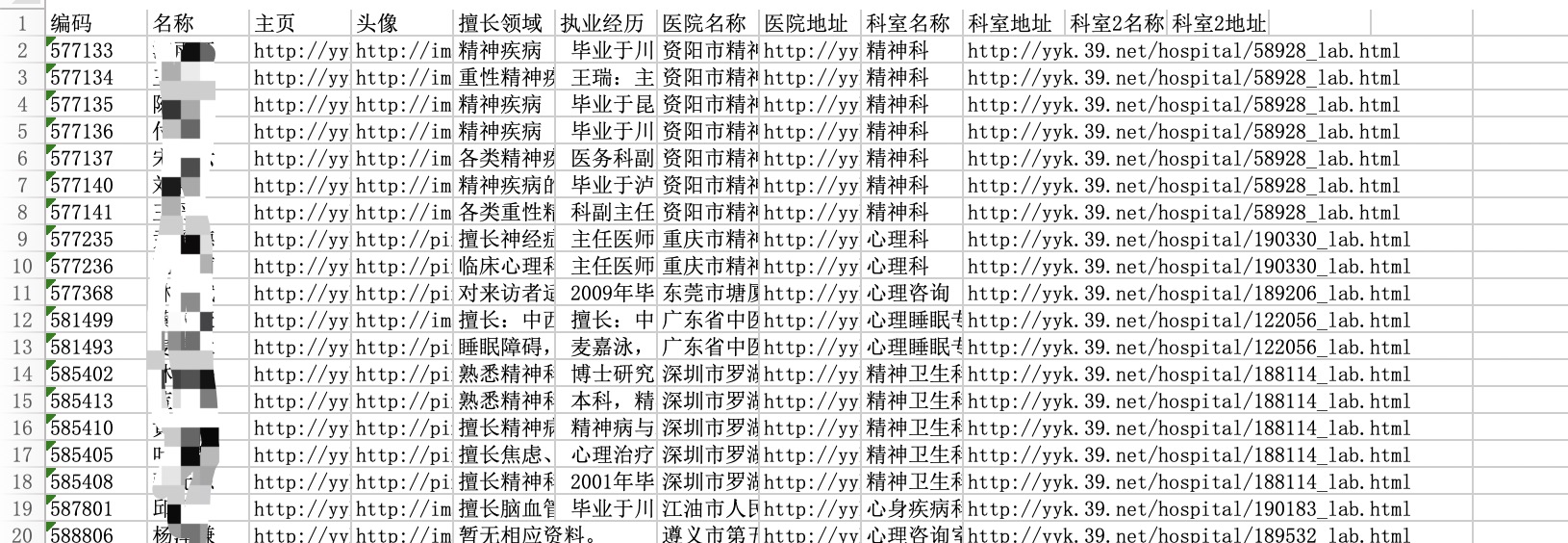
医生头像

源码
https://github.com/HuDaQian/PythonDemo/tree/master/Doctor_list