1、准备模块
这个没什么,和医生的一样
2、分析网页
列表页就不说了,跟医生的一样,医院首页的信息是
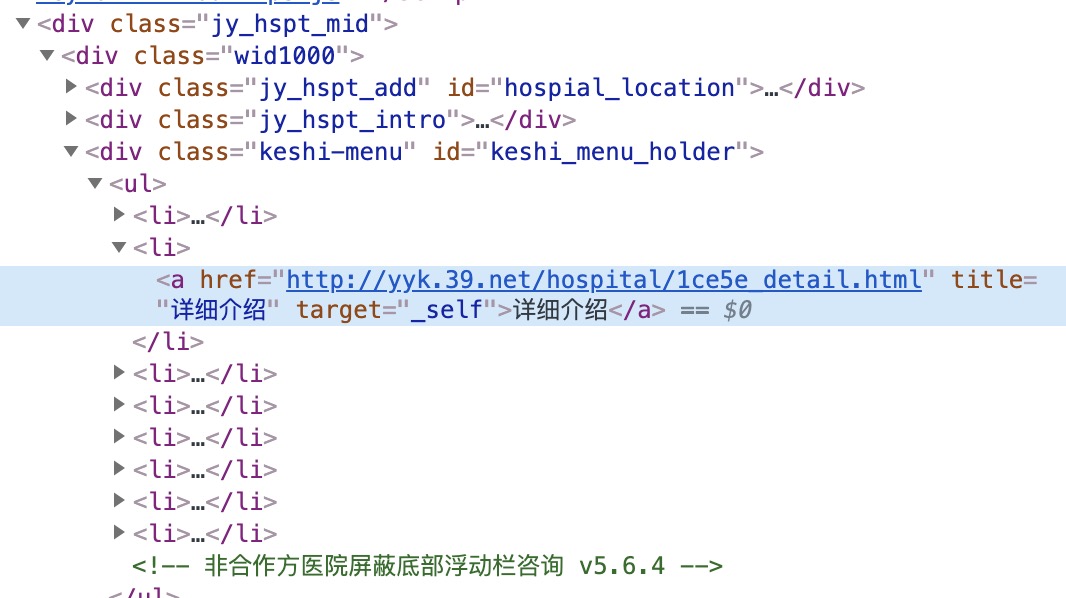
然后分析了下详细介绍的地址

最后分析需要的数据
等级、别名
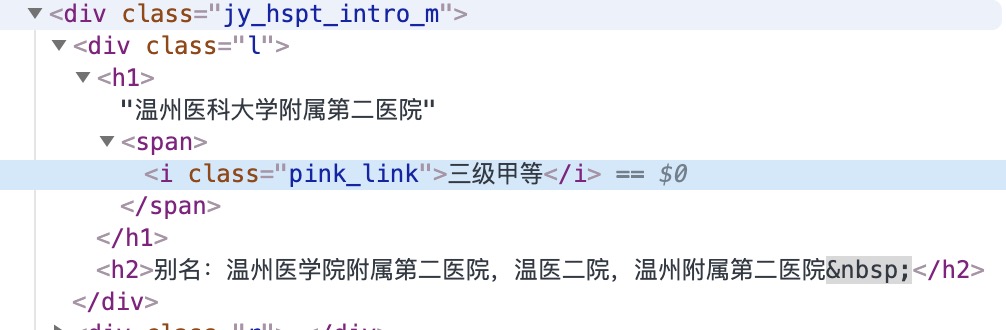
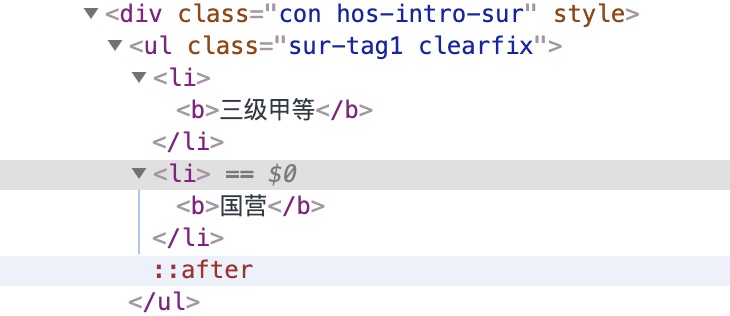
标签
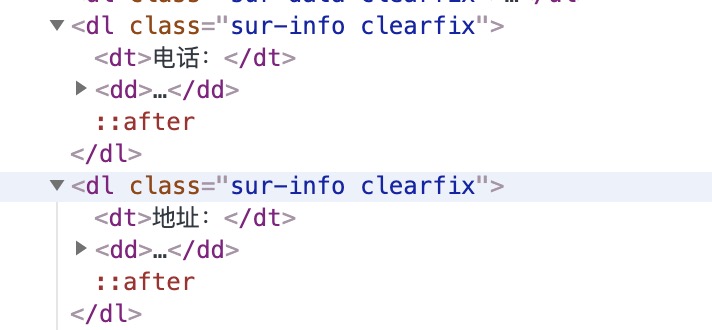
电话、地址
简介等信息
3、核心代码
主要是类型一样的处理
比如:地址、电话
#电话和地址还有分院放一起处理
phone = ''
adress = ''
son_name = ''
son_url = ''
info_list = soup.select('dl[class="sur-info clearfix"] dd')
for i in info_list:
# print(repr(i.previous_element.previous_element))
if repr(i.previous_element.previous_element) == "'电话:'":
phone += str(i.span.get_text() + '\n')
elif repr(i.previous_element.previous_element) == "'地址:'":
adress += str(i.span.get_text() + '\n')
elif repr(i.previous_element.previous_element) == "'分院:'":
son_name += str(i.span.get_text() + '\n')
son_url += str(i.a.get('href') + '\n')
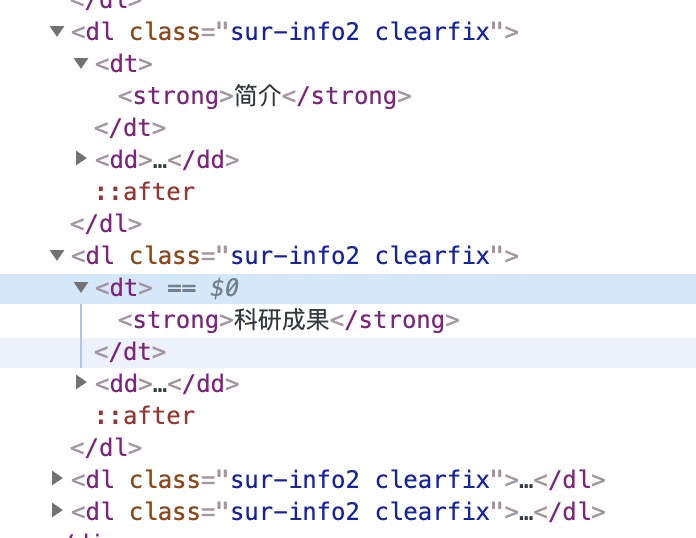
简介等信息
#简介、科研成果、获奖荣誉和先进设备放一起处理
detail = ''
scientific = ''
prize = ''
equip = ''
detail_list = soup.select('dl[class="sur-info2 clearfix"] dd')
for i in detail_list:
# print(repr(i.previous_element.previous_element))
if repr(i.previous_element.previous_element) == "'简介'":
# print(i.get_text())
detail += str(i.get_text() + '\n')
elif repr(i.previous_element.previous_element) == "'科研成果'":
# print(i.get_text())
scientific += str(i.get_text() + '\n')
elif repr(i.previous_element.previous_element) == "'获奖荣誉'":
# print(i.get_text())
prize += str(i.get_text() + '\n')
elif repr(i.previous_element.previous_element) == "'先进设备'":
# print(i.get_text())
equip += str(i.get_text() + '\n')
#4、开始抓取
送上源码:
https://github.com/HuDaQian/PythonDemo/tree/master/Hospital_list